AIエージェント設計の本質は『中央DB OS』|動画100本作っても売上ゼロの理由と『1素材→100出力』アーキテクチャ全公開
ChatGPTで動画は誰でも作れる時代。でも100本作っても売上は動かない。本記事では、AI動画量産が資産にならない構造的理由と、中央DB OSを核にした8装置自動派生アーキテクチャ、AIツール利用者とエージェンティックエンジニアを分ける『1素材→100出力』設計の全体像を、年商10億社長の実例を交えて約10,000字で解説します。
「YouTube に社長の動画を AI で量産してほしい」── 先日、 年商 10 億の経営者からそんな相談がきました。 これに対する私の即答は「お断りします」 でした。 100 本作っても、 売上は動かないからです。
本記事は、 ChatGPT や HeyGen が誰でも使える時代になってもなお、 AI 動画の量産が 売上の伸びに直結しない構造的な理由 と、 その代わりに作るべき 「中央 DB OS」 アーキテクチャ の設計図を全公開する、 一本道のピラー記事です。 年商 10 億社長の実例、 8 装置への自動派生図、 1 素材から 145 配信ノードへ展開する具体的な計算式、 そして AI ツール利用者と「エージェンティックエンジニア」 を決定的に分ける 4 階層モデルまで、 約 10,000 字で書き切ります。
読み終えるとき、 あなたの手元には「AI で動画作って」 から「AI で動く中央 DB を設計して」 へ、 経営者の思考が転換するための最短の青写真が残ります。
なぜ AI 動画を 100 本量産しても売上ゼロになるのか — 使い捨て構造の 5 欠陥
冒頭の社長は、 月商換算で約 8,000 万円規模、 YouTube チャンネルの登録者は数万人。 「動画 10 本を 1,000 万円規模で発注したい」 という、 普通なら歓迎すべき案件でした。 私はこう返しました。
「動画 10 本を作って、 売上は動きますか?」
社長は固まり、 こう続けました。
「いや、 量産すれば多少は…」
私の答えはこうです。
「100 本作っても、 売上ゼロの会社をたくさん見てきました」
なぜか。 AI 動画というアウトプットには、 構造的に 「資産になれない 5 つの欠陥」 が組み込まれているからです。
欠陥①: その都度ゼロから作る
動画 1 本ごとに、 ネタ出し → 台本 → 撮影 (or アバター合成) → 編集 → 公開、 という工程をゼロから繰り返す。 2 本目を作る時、 1 本目の知見が再投入される仕組みがありません。 ChatGPT で台本生成、 HeyGen でアバター合成、 と工程の中身を AI 化しても、 「毎回ゼロから」 という構造そのものは変わらないままです。
欠陥②: データが蓄積されない
撮影した素材、 視聴データ、 コメント反応、 これらがすべてバラバラのプラットフォームに散らばり、 翌月の意思決定に使えません。 「6 月にバズった企画と 11 月に滑った企画の差」 を分析しようにも、 データが横断的に紐付いていないので、 翌年も同じ間違いを繰り返します。
欠陥③: 同じ素材を別目的に再利用できない
同じ社長の発言が、 短尺動画にも、 メルマガネタにも、 ブログ記事にも、 営業資料にも、 商品 LP にも横展開できれば、 1 つの収録から 50 のアセットが生まれます。 しかし「動画を作って終わり」 の発注では、 その素材は YouTube に貼り付いて二度と動かない 1 ファイルになります。
欠陥④: 営業・顧客の声を横展開できない
経営者が現場で吸い上げた営業マンの「お客様の本音」、 アンケートで集めた顧客の困りごと。 これらが動画制作プロセスの外側にある限り、 動画はいつまでも「経営者が話したいこと」 で止まり、 「お客様が聞きたいこと」 にチューニングされません。 結果、 視聴は伸びても問い合わせは伸びない、 という典型的な詰まり方になります。
欠陥⑤: 効果測定の物差しが主観に依存する
「再生数」 「いいね」 を眺めて「いい感じ」 「微妙」 と感想を述べるだけで、 売上のリフト、 LTV の変化、 リード獲得コストの低下、 という経営数値に紐付けて評価する仕組みがない。 主観で続けるか止めるかを判断している限り、 改善ループは閉じません。
この 5 欠陥は、 「AI 動画ツールを乗り換えれば解消されます」 系の発想では絶対に解消されません。 なぜなら、 これらは 動画というアウトプットの個別性能の問題ではなく、 アウトプットを生み出す「構造」 そのものの問題 だからです。 構造を変えなければ、 ツールをいくら最新化しても 5 欠陥は再現します。
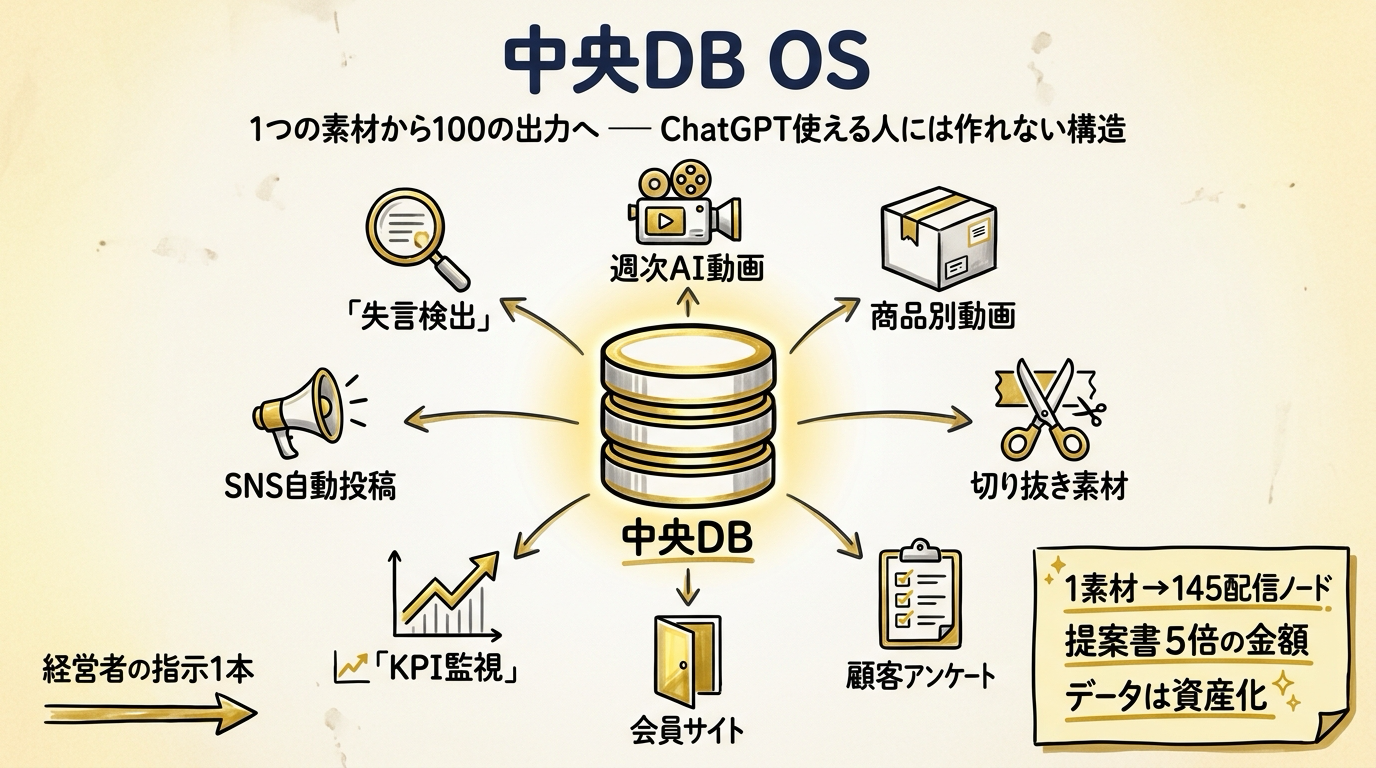
中央 DB OS とは何か — 8 装置に自動派生するアーキテクチャの全体図
では、 動画量産の代わりに何を作るのか。 答えは 「中央 DB OS」 です。
中央 DB OS とは、 経営者の発言、 営業マンの会話ログ、 顧客アンケート、 過去動画の文字起こし、 商品データ、 SNS のリプライ。 これら すべての一次情報を 1 箇所の構造化データベース (中央 DB) に蓄積し、 そこから複数の自律エージェントが「読み込み → 生成 → 配信 → 結果を DB に書き戻し」 を回し続ける、 経営オペレーティングシステムのことです。
私が今、 経営者クライアントに対して設計しているスタンダード構成は、 中央 DB + 8 装置 です。
中央 DB OS の 8 装置一覧
- 週次 AI 動画装置: 社長の発言ログから今週の主題を抽出し、 ショート 3 本 + 縦長 1 本を自動生成
- 商品別動画装置: 商品データと過去顧客の質問をマッチングし、 商品ごとに「よくある疑問への回答動画」 を量産
- 切り抜き素材自動抽出装置: 過去 1 時間動画から「30 秒で完結する名言」 を自動切り出し
- 顧客アンケート集計装置: 寄せられた声を毎日 RAG 化し、 「次に作るべきコンテンツの仮説」 を提案
- 会員サイト + イベント告知装置: コミュニティ会員の閲覧履歴に合わせて、 個別告知を自動発火
- KPI 監視ダッシュボード装置: 動画再生、 メルマガ開封、 LP CVR、 売上数値を 1 画面で横断
- SNS 自動投稿装置: X / Instagram / TikTok / YouTube / LinkedIn に「同じ核から枝分かれした 5 種類の表現」 を配信
- 失言・不一致検出エンジン: 過去発言と新規発言の論理矛盾を検出し、 「過去と違うこと言ってませんか」 を経営者にアラート
それぞれが独立した「装置」 として動きますが、 すべてが 中央 DB を読み書きする ことで結合しています。 つまり、 ある装置が拾った気付きが別の装置のインプットになる、 という「飼料が循環する」 設計です。
「装置」 が 8 個ある意味
経営者が必要としているのは、 単発の動画ツールでも、 個別の自動化スクリプトでもありません。 「事業全体のオペレーションを自分の手から離す」 ことです。 そのためには、 8 個の機能領域 (発信 / 商品 / 編集 / 顧客理解 / 会員 / 数値管理 / SNS / リスク管理) が、 共通の真実の源 (中央 DB) から派生していることが不可欠です。 1 装置だけ自動化しても、 残り 7 領域が手動で動いている限り、 経営者の手は空きません。
8 装置がもたらす経営インパクト
| 観点 | 丸投げ型 (AI ツール利用者) | 中央 DB OS 型 (エージェンティックエンジニア) |
|---|---|---|
| 1 素材からの派生出力 | 1 本 | 100 本以上 |
| データの蓄積 | ゼロ (使い捨て) | すべて DB に蓄積、 学習素材化 |
| 横展開 | 不可 (媒体ごとに独立) | 8 装置に自動派生 |
| 効果測定 | 主観・断片的 | KPI ダッシュボードで自動横断 |
| 1 度作った後の労力 | 毎回ゼロから | 設定 1 度で永続稼働 |
| 結果 | 労働 | 資産 |
この差は、 「ツールを 1 つ追加すれば埋まる差」 ではありません。 設計思想そのものが違います。
1 素材から 145 配信ノードへ — 29 人 × 5ch の派生計算
「1 素材から 100 出力」 という言い方は感覚的すぎるので、 具体的な数字で示します。
ある経営者クライアントは、 営業マンが 29 人 在籍する組織を持っています。 中央 DB OS の導入前と後で、 1 つの社長音声がどう派生するかを比較します。
丸投げ型 (Before)
社長音声 1 つ → 動画編集者が 1 本の YouTube 動画にまとめる → 公開。 配信ノードは 1。
29 人いる営業マンには、 「YouTube に動画上がったので各自シェアしてください」 という社長メッセージが流れますが、 結局シェアしない人が大半。 実質配信ノードは 2-3 に過ぎません。
中央 DB OS 型 (After)
社長音声 1 つを中央 DB に投入すると、 次の派生が 自動で 走ります。
- 媒体軸: YouTube 本編 / YouTube Shorts / X / Instagram / TikTok の 5 チャネル
- 発信主体軸: 社長公式 + 営業マン 29 人 = 30 主体
- ただし営業マン側はパーソナルブランド配慮で 3 ch (X / Instagram / LinkedIn) に絞ると、 29 × 3 = 87 ノード
- 社長公式の 5 ch = 5 ノード
- ここに「商品 LP に埋め込む解説動画」 と「メルマガ本文」 と「営業資料 1 ページ追加」 の派生を加えると、 さらに 約 53 ノード
合計: 5 + 87 + 53 = 約 145 配信ノード
1 つの社長音声から、 1 ノードと 145 ノード。 同じ素材の届く広さが 100 倍以上違う、 という具体的なインパクトです。
しかも、 その先で蓄積が始まる
145 ノードのうち、 営業マン経由の 87 ノードについては、 「どの営業マンの投稿が反応を集めたか」 「どの商品の解説が問い合わせに繋がったか」 が中央 DB に戻ってきます。 翌週の社長音声の主題選定が、 主観ではなく「先週ヒットした切り口」 に基づいて自動的に最適化される。 これが「使い捨てでなく蓄積される」 という言葉の実態です。
3 ヶ月続けると、 中央 DB には「どんな主題 × どの営業マン × どの媒体」 で反応が出るかの相関データが数千行単位で溜まります。 これが翌月の AI エージェントの精度を上げ続け、 雪だるま式に効果が増していく。 丸投げ型の発注では絶対に到達できない領域です。
AI ツール利用者と「エージェンティックエンジニア」 の決定的な違い — 労働 vs 資産
ここまでで、 「動画 100 本」 と 「中央 DB OS」 が量的にも質的にも別世界であることが見えてきました。 ここで、 私が最近ずっと使っている言葉に整理を入れます。
「AI ツール利用者」 とは
ChatGPT を使えます、 HeyGen で AI 動画が作れます、 Canva の AI で LP が作れます。 これらは全て AI ツール利用者 と呼ぶレベルです。
特徴は、 「動画作って」 「LP 作って」 「SNS 投稿して」 と単発のアウトプットを依頼するパターンの繰り返し であること。 毎回ゼロから作って、 終わったらデータも消える。 これは 労働 です。 人がやるか AI がやるかの違いだけで、 構造は変わりません。
「エージェンティックエンジニア」 とは
エージェンティックエンジニア (Agentic Engineer) は、 これとは 設計のレイヤーが違います。
エージェンティックエンジニアが作るのは アウトプットそのもの ではなく、 「データが蓄積される構造」 と 「1 素材から 100 出力に派生する仕組み」 です。 1 度設計したら、 動き続けます。 これは 資産 です。
違いを 1 行で
AI で動画を作れます、 はアマチュア。 動画を自動で量産するシステムを作れます、 がエージェンティックエンジニア。 そして本質は、 中央 DB こそが鍵。
この 3 行が、 ここ最近、 私が一貫して打ち出している立場です。
なぜこの区別が経営者にとって決定的か
経営者が AI 活用について「うちでも何かやらせなきゃ」 と考える時、 ほとんどの場合は AI ツール利用者を社内に増やす方向に動いてしまいます。 「ChatGPT 講座を全社員に受けさせる」 「動画編集 AI ツールを契約する」 「SNS 投稿 AI を導入する」── これらは確かに作業時間を短縮しますが、 資産化はしません。
むしろ、 ツール契約が増えるほど、 オペレーションは複雑化し、 データはより分散します。 経営者の手が空くどころか、 「うちの AI ツール、 結局誰が管理するんだっけ」 という新しい労働が生まれる。 「AI 導入したら忙しくなった」 と苦笑いする経営者を、 私はここ 1 年でもう数十人見ています。
エージェンティックエンジニアを 1 人迎え入れる、 あるいは経営者自身がエージェンティックエンジニアの設計思想を学ぶ、 という選択をしない限り、 AI 投資は永久に「労働の置き換え」 で止まります。
中央 DB 設計の 4 階層モデル — プロンプト → SOP → エージェント → 中央 DB
「中央 DB OS が良いのは分かった。 では何から作ればいいのか」 という質問への答えを、 構造化された 4 階層モデル で示します。
私が現場で使っている設計思想はこれです。
┌───────────────┐
│ 中央 DB │ ← 経営者がここを設計する (3 階)
└───────────────┘
↑
┌───────────────┐
│ エージェント群 │ ← 8 装置の自律実行 (2 階)
└───────────────┘
↑
┌───────────────┐
│ SOP │ ← エージェントが従う手順書 (1 階)
└───────────────┘
↑
┌───────────────┐
│ プロンプト │ ← 個別の指示テンプレート (0 階)
└───────────────┘0 階: プロンプトが書ける
ChatGPT に「こういう動画台本を書いて」 と指示できるレベル。 ほとんどの「AI 活用研修」 はここで終わります。 プロンプトは個別の指示で、 再現性も継承性もありません。
1 階: SOP が書ける
「同じプロンプトを再現性高く回すための手順書」 が書けるレベル。 ここに到達して初めて、 自分以外の人 (もしくは別の AI) に作業を引き継げます。 SOP は「いつ・どの順で・どのプロンプトを呼ぶか」 の標準化です。
2 階: エージェントが組める
SOP に従って自律的に動く「エージェント」 を組めるレベル。 動画装置 1 つ、 SNS 装置 1 つ、 と単発で組めるのはここまで。 ただしまだ「縦割り」 で、 装置間でデータが繋がっていません。 SaaS でいえば「Make / Zapier で 1 本の自動化を組める」 のがこのレベルです。
3 階: 中央 DB が設計できる
複数のエージェントが共有する 真実の源 (中央 DB) のデータモデルを設計し、 全装置をその DB 上で結線できるレベル。 ここに立てる人だけが、 私が呼ぶ「エージェンティックエンジニア」 です。 「テーブル定義」 「外部キー」 「正規化レベル」 「ベクトル化対象」 を、 事業ドメインの言葉と接続して描けるかどうかが分水嶺になります。
経営者が 3 階に立つ必要性
経営者が 0-2 階の作業を全部自分でやる必要はありません。 むしろやるべきではない。 経営者がやるべきことは、 3 階のデータモデル設計、 つまり「自分の事業にとって、 何が真実の源として残るべきか」 を決めることだけです。
「お客様の声 = 顧客 ID + 商品 ID + 発話日時 + 感情ラベル」 という最小スキーマを定義するか / しないか。 「営業会話ログ = 営業担当者 ID + 顧客 ID + 商談フェーズ + 発話テキスト」 と定義するか / しないか。 ここの設計が、 下の 8 装置の精度を上限まで決めてしまいます。
私が経営者向け合宿で 3 日間ぶっ通しでやっているのは、 この 3 階の設計図を一緒に描く 作業です。 0-2 階はあとで AI が肩代わりしてくれるからです。 経営者の希少リソースを 3 階に集中投下する、 という意思決定が、 OS 型移行の出発点になります。
経営者の依頼が「動画作って」 から 「中央 DB 作って」 に変わる時 — 引退最短ルート
最後に、 経営者にとっての実利の話です。
「動画 10 本 1,000 万円」 を断った理由
冒頭の社長案件、 私は最初に「お断りします」 と返した上で、 こう続けました。
「動画 10 本ではなく、 中央 DB OS の最小構成を 1 つ作りませんか。 8 装置すべては無理でも、 まず週次動画装置 + 顧客アンケート集計装置 + SNS 自動投稿装置の 3 装置で始められます。 提案書を書き直してきてください」
社長は数日後、 5 倍の金額の提案書 を出し直してきました。 そして、 こう言いました。
「ようやく分かった。 動画は経費だけど、 DB は資産だ」
ここが、 経営者の発想が転換する 1 点目です。 経費は P/L に消え、 資産は B/S に残る。 同じ AI 投資でも、 計上される場所がそもそも違う。
「動かないシステム」 を持つことが、 引退の最短ルート
経営者にとっての究極の自由は、 「自分が現場から退いても、 売上が動き続ける状態」 を作ることです。 これを実現する経路は、 ロジック上 3 つしかありません。
- 人を増やす: ただし管理コストが線形に増え、 退職リスクも増える
- 権限委譲する: ただし任せる人物のレベルに天井が左右される
- 自律稼働システムを作る: 中央 DB OS + 8 装置で、 人に依存しない仕組み化
3 番目だけが、 経営者の手が完全に空く道です。 そして、 3 番目を作れる人材が「エージェンティックエンジニア」 です。 1-2 番目を選んだ経営者が、 5 年後に「結局自分が一番動いている」 と嘆くケースを、 私は山ほど見てきました。
「直接発注」 をやめるという決断
あなたが直接、 動画を発注している限り、 それは資産になりません。 あなたが直接、 LP を発注している限り、 それは資産になりません。 あなたが直接、 SNS を投稿させている限り、 それは資産になりません。
直接発注を止めて、 中央 DB を 1 度設計する。 そこから 8 つのエージェントを派生させる構造に投資する。 これを 1 度作れば、 あなたは動かなくていい。
経営者がやるべき意思決定 5 つ
中央 DB OS への移行を検討する経営者が、 自分自身に問うべき問いは次の 5 つです。
- 今、 私の事業で「使い捨てになっている素材」 は何か (動画? 営業ログ? 顧客の声?)
- それを 100 倍に派生させたら、 どんな配信ノードが見えてくるか
- 真実の源として中央 DB に乗せるべき「最小スキーマ」 は何か
- 8 装置のうち、 まず 3 つに絞るとしたら、 どの 3 つから始めるか
- 私が「直接発注を止める」 と決めるための、 心理的ブロックは何か
この 5 問に答えが出た時、 あなたはもう「動画 10 本を発注する経営者」 ではなく、 「中央 DB OS の設計図を描く経営者」 に変わっています。
まとめ — AI で動画を作れますはアマチュア。 中央 DB こそが鍵
本記事の核を 4 行で。
- AI 動画は 100 本作っても売上ゼロ。 使い捨てに 5 欠陥が組み込まれているため。
- 代わりに作るべきは中央 DB OS。 1 素材から 145 配信ノードに自動派生する設計。
- AI ツール利用者と エージェンティックエンジニアの違い は労働 vs 資産。 設計レイヤーがそもそも違う。
- 経営者がやるべきは 3 階のデータモデル設計。 0-2 階は AI が肩代わりする。
そして 1 フレーズに圧縮するなら、 これだけです。
AI で動画を作れますはアマチュアで、 動画を自動で量産するシステムを作れますがエージェンティックエンジニア。 そして本質は、 中央 DB こそが鍵。
あなたが中央 DB OS の設計図を描けるようになるために
私はこの 4 階層の設計思想を、 全国の経営者・エージェンティックエンジニア候補と一緒に 3 日間で実装するプログラム を開催しています。
- 日程: 2026 年 6 月 6 日 (土) - 8 日 (月) の 3 日間
- 会場: 名古屋 (詳細はオープンチャットでご案内)
- 定員: 50 名で締切
- テーマ: 中央 DB + 8 装置の自律エージェント群を、 あなたの事業の素材で設計する
「動画 10 本を発注する経営者」 を卒業し、 「中央 DB OS の設計図を描ける経営者」 になりたい方は、 大和 ViSiONARY のオープンチャット からご連絡ください。
メルマガでは、 本記事のような「AI ツール利用者 → エージェンティックエンジニア」 の道筋を、 週次でもう少し短くまとめて配信しています。 経営者向けの構造化された発信のみ。 メルマガ登録はこちら からどうぞ。
関連記事
- Claude Code は翌日忘れる — CLAUDE.md 4 階層と SOP 注入で『Obsidian × Claude Code』 を超えるエージェント記憶設計 — 中央 DB の前段、 「エージェントの記憶階層」 編。
- AI エージェント設計を 7 チャネルに展開する全体図 — 8 装置の前段にあたる、 5-7 ch 派生のフレームワーク。
- HeyGen × AI アバターで顔出しなしショート動画を月 30 本自動化する完全ガイド — 8 装置のうち「週次 AI 動画装置」 の単体実装解説。
- Claude Code 入門 — エージェント設計の最初の一歩 — 4 階層モデルの 0-1 階を実装で押さえるための入門編。
この記事が役立ったなら、次のステップへ
専門家と一緒に、あなたのAI活用を加速させましょう
白石達也
BlueLamp創業者。52のAIエージェントを開発し、企業のAI導入を支援。 Aquaphotomics MCP(12,800+論文処理)開発者。Claude Code専門家。
プロフィールを見る →