Claude Code は翌日忘れる — CLAUDE.md 4 階層と SOP 注入で『Obsidian × Claude Code』を超えるエージェント記憶設計
「メモリに入れて」と頼んでも翌日には忘れている ── これは Claude Code の不具合ではなく仕様です。CLAUDE.md 4 階層 (org/user/project/local) と Auto Memory の境界、Obsidian vault に全部入れる『2 流設計』との違い、SOP ファイル + load_knowledge による『1 流注入』までを 15,000 字で解説します。

「エージェントに『二度と間違えるな』『これメモリに入れておけ』と言うと、そのときは『はい、わかりました』と返してくる。でも翌日また同じミスをする。なぜですか?」── 先日のグループコンサルティングで受けた、本質的な質問でした。
答えから書きます。Claude Code は、覚えていません。「覚えました」と返してくるのは、そのセッションの中だけの話です。ターミナルを閉じて翌日別のディレクトリで Claude Code を立ち上げた瞬間、きれいに忘れます。これは不具合ではなく 設計 です。仕組みを理解しないまま「メモリに入れて」と頼み続けても、永遠に同じミスを踏みます。
本記事では、Claude Code が読み込む 4 階層の CLAUDE.md (マシン全体 / ユーザー全体 / プロジェクト / ローカル個人) と Auto Memory の正確な動作仕様を整理した上で、巷で流行している「Obsidian × Claude Code でセカンドブレイン」設計が、なぜエージェンティックエンジニアから見ると 2 流止まり なのかを構造から解説します。そして、3 日前に私自身が踏んだ Day 9 リプライエージェントの 23 分損失を、メモリではなく SOP ファイルで永久解決 した実証ログまで全公開します。読み終えるとき、手元には「エージェントが翌日も賢くなり続ける」記憶設計の青写真が残ります。
1. Claude Code は「翌日忘れる」 — メモリの仕組みと 4 階層 CLAUDE.md
最初に、最も誤解されている点から潰します。Claude Code (Anthropic 公式 CLI) は、会話ごとに脳がリセットされる エージェントです。あなたが昨日「次から字幕を必ず付けて」と指示しても、翌朝同じディレクトリで立ち上げ直した時、そのセッションのコンテキストは消えています。残るのは、起動時にディスクから読み込まれた設定ファイル だけです。
ここで言う「設定ファイル」が、Claude Code の文脈では CLAUDE.md です。これは公式に文書化された 4 階層の優先順位を持つマークダウンファイルで、Claude Code は起動するたびにこの 4 階層を順に読み込み、上位ほど優先される形で 1 つの「初期コンテキスト」を組み立てます。
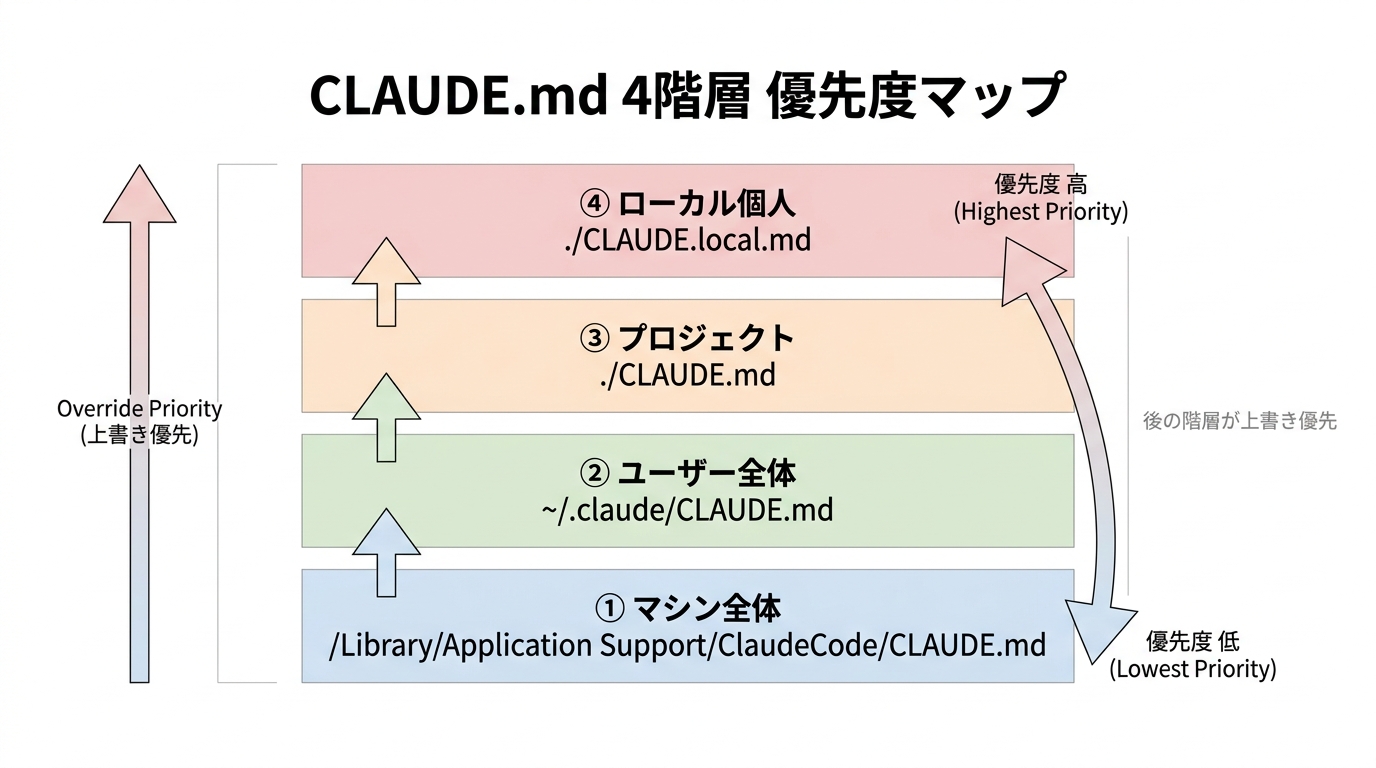
4 階層の中身
| 優先度 | 階層 | パス | 用途 |
|---|---|---|---|
| ① 最低 | マシン全体 | /Library/Application Support/ClaudeCode/CLAUDE.md (macOS) | 組織配布のグローバル設定 |
| ② | ユーザー全体 | ~/.claude/CLAUDE.md | 個人共通の絶対原則 |
| ③ | プロジェクト | ./CLAUDE.md | リポジトリ固有のルール |
| ④ 最高 | ローカル個人 | ./CLAUDE.local.md | 共有しない個人設定 |
後ろの階層ほど上書き優先されます。プロジェクト直下の ./CLAUDE.md でユーザー全体の指示を上書きでき、./CLAUDE.local.md でそれをさらに上書きできる、入れ子構造です。
「Auto Memory」 という別系統
ここまでが静的な階層ファイル。これとは別に、Claude Code には Auto Memory という動的な仕組みがあります。~/.claude/projects/<プロジェクトディレクトリのハッシュ>/memory/ 配下に、セッション中に得られた情報が自動的に追記されていきます。「ユーザーが Go 10 年のキャリアを持つ」「pre-commit hook がしばしば失敗する」のような、その プロジェクトに紐付いた知見 がここに蓄積されます。
そして、この Auto Memory はプロジェクトディレクトリ単位で完全に分離されています。動画生成プロジェクトで「字幕を忘れるな」を覚えさせても、翌日ブログ記事のプロジェクトディレクトリで立ち上げ直したら、そのメモリは存在しないも同然です。「覚えました」と返ってきた記憶は、別ディレクトリでは読み込まれません。
だから「翌日忘れる」
整理すると、エージェントが翌日も覚えていられるのは次の 2 経路だけです。
- CLAUDE.md (4 階層のいずれか) に明文化された情報
- 同じプロジェクトディレクトリ内の Auto Memory に書き込まれた情報
これ以外の「セッション内の口頭指示」は、ターミナルを閉じた瞬間に消えます。「メモリに入れて」と頼んだあなたの言葉がどちらの経路に届いたのかを意識しないまま依頼を続ければ、エージェントは「はい」と返事をしながら永遠に忘れ続けます。これが、冒頭のグルコン質問の正体です。
ここまでが基礎仕様の整理です。次章からは、この 4 階層をどう書き分けるか、Auto Memory をどう運用するか、そして そもそも「メモリに入れて」と頼むこと自体が 3 流である という核論まで踏み込みます。
2. CLAUDE.md の書き方 — 4 階層をどう使い分けるか
CLAUDE.md は単なる「メモ書きファイル」ではありません。エージェントの 初期コンテキストとして起動時に必ず読み込まれる ため、ここに書く内容が多すぎればトークンが浪費され精度が落ち、少なすぎれば期待した動作をしません。階層ごとの 書く / 書かない の判断軸を明示します。
階層 ② ~/.claude/CLAUDE.md (ユーザー全体)
書くべきもの:
- 全プロジェクト横断の絶対原則。例: 「
prisma db push --accept-data-lossは絶対に実行しない」(私の環境では実際に書いてあります) - デプロイ先・サービス名の対応表。誤ったプロジェクトに deploy する事故防止
- 言語スタイル / 口調 / 改行ルール 等、すべての作業で守ってほしい横串の指針
書かない方がよいもの:
- 特定プロジェクトでしか使わないルール
- 特定タスクでしか必要ないチェックリスト (動画字幕の埋込ルール等)
理由: ここに書いたものは すべての Claude Code セッションでコンテキストに乗ります。動画と無関係なリプライエージェント作業中にも字幕ルールが流し込まれ、トークンが無駄になり、ノイズが増え、精度が下がります。これが本記事の核論にも繋がる「過剰メモリの罠」です。
階層 ③ ./CLAUDE.md (プロジェクト)
書くべきもの:
- そのプロジェクトの ディレクトリ構造の概要
- 環境変数 / DB / API キーの管理ルール
- 主要なコマンド (build / deploy / test の実行方法)
- そのプロジェクト固有の 禁止事項
- そのプロジェクトの ドキュメント許可リスト (例: 私の場合は
docs/SCOPE_PROGRESS.md/docs/requirements.md/docs/DEPLOYMENT.md以外の md 作成禁止)
書かない方がよいもの:
- 個人の好み (これは
./CLAUDE.local.mdか~/.claude/CLAUDE.mdで) - 全プロジェクト共通のルール (重複する)
階層 ④ ./CLAUDE.local.md (ローカル個人)
書くべきもの:
- 自分のマシン固有の API トークン置き場の説明
- そのプロジェクトに対して、チームには共有しない 自分の作業ルール
書かない方がよいもの:
- 機密情報そのもの (パスワード / トークンの値)。これらは別のシークレットマネージャーへ
- チームで共有すべきルール (それは
./CLAUDE.md)
階層 ① マシン全体 (組織配布)
私の使い方では現状ほぼ未使用です。組織で Claude Code を配布管理しているチームが、全社共通のセキュリティ規約等を書く場所として想定されています。個人開発・小規模チームでは ② ③ ④ で十分足ります。
「3 階層を使い分ける」だけで 80% 解決する
実務上、~/.claude/CLAUDE.md (ユーザー全体) と ./CLAUDE.md (プロジェクト) を 明示的に書き分ける だけで、エージェントの再現性は劇的に上がります。私の ~/.claude/CLAUDE.md には、過去に実際に起きた事故から導出した禁止事項 (2026-04-12 の Prisma データ消失事故、2026-04-23 の ainotes 早期保存事故 等) が日付付きで書かれています。
ここで重要なのは 事故が起きるたびに追記する という運用です。後の章で詳しく書きますが、エージェント時代の「学習」とは、ミスを CLAUDE.md または SOP ファイルに明文化していく行為そのもの です。エージェントが学ぶのではありません。あなたが、エージェントの初期コンテキストを編集することで学ばせる のです。
3. Auto Memory はプロジェクト単位 — 別ディレクトリでは消える事実
CLAUDE.md と並ぶもう一つの記憶経路、Auto Memory の動作仕様を正確に押さえます。ここで誤解している人が最も多いポイントです。
保存場所
Auto Memory の実体は、各 OS のホームディレクトリ配下にあります。
~/.claude/projects/<プロジェクトパスをエンコードしたハッシュ>/memory/例えば私のメインプロジェクトの 1 つは、以下のような path 構造で保存されています。
/Users/tatsuya/.claude/projects/-Users-tatsuya--claude-monsters-4fe7e79a-c19c-4e73-8a7c-fca022711018/memory/-Users-tatsuya-... の部分は、起動時にいたディレクトリの絶対パスをスラッシュをハイフンに置換しただけのものです。つまり どのディレクトリで claude を立ち上げたか によって、読み書き先の memory フォルダが切り替わります。
別ディレクトリ = 別の脳
ここから本題です。例えば次の 2 つは Claude Code から見て 完全に独立した脳 として扱われます。
| あなたから見たプロジェクト | Auto Memory パス |
|---|---|
~/Desktop/動画生成/ | ~/.claude/projects/-Users-xxx-Desktop-動画生成/memory/ |
~/Desktop/ブログ記事/ | ~/.claude/projects/-Users-xxx-Desktop-ブログ記事/memory/ |
動画生成プロジェクトで「字幕は per-cut clip 内 burn-in (overlay chain 禁止)」を Auto Memory に学習させても、翌日ブログ記事プロジェクトで claude を起動した瞬間、その記憶は読み込まれません。ディレクトリが違えば、脳が違う のです。
グローバルメモリは存在しない
「じゃあ全プロジェクトを横断する Auto Memory はないの?」と聞かれます。答えは NO、現時点 (2026 年 5 月) の Claude Code には、全プロジェクトを横断する自動メモリ機能は存在しません。横断したいなら、自分で ~/.claude/CLAUDE.md (ユーザー全体 CLAUDE.md) に書き込むしかありません。
でも、すべてを「ユーザー全体」に書くのは間違い
ここで多くの人がやらかします。「翌日も忘れさせたくないから、全部 ~/.claude/CLAUDE.md に書こう」と考えてしまうのです。
それは構造的に間違いです。前章で触れた通り、~/.claude/CLAUDE.md に書いたものは、動画と無関係な作業中にもエージェントの context に乗ってきます。トークンが浪費され、ノイズが増え、精度が下がります。
つまり、Auto Memory は「プロジェクト単位で隔離されている」という制約と、CLAUDE.md は「常に context に乗ってくる」という性質を、両方の制約のまま運用することがエージェント設計の出発点です。「全部覚えさせる」「全部忘れない」の どちらも本質的に不適切 という、一見矛盾した結論から始める必要があります。
これが、次章で扱う「3 流のメモリ利用者」と「1 流の SOP 設計者」を分ける根本構造です。
4. 「メモリに入れて」は AI 利用 3 流 — なぜ構造化の放棄なのか
ここから本記事の核論に入ります。私は、エージェントに「これメモリに入れて」と頼むことを AI 利用 3 流の典型行動 だと考えています。表現はやや強いですが、これは煽りではなく、構造的な区別です。理由を順に書きます。
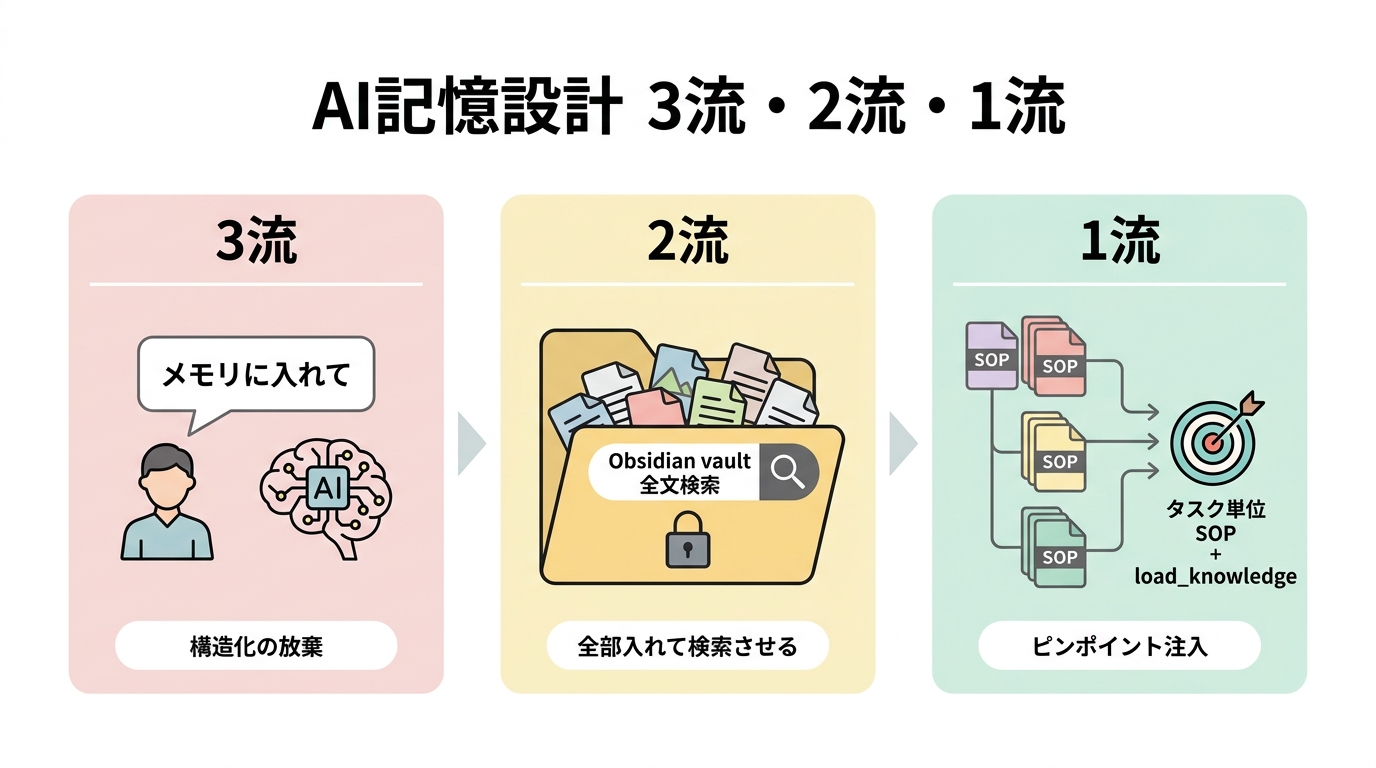
3 流: 「全部覚えておけ」と AI に丸投げする
「メモリに入れて」「次から覚えていて」と頼む人は、自分で記憶のスコープを設計していません。エージェントに「いい感じに覚えておいて」と丸投げしている状態です。これが構造化の放棄です。
何が起きるか:
- 動画字幕ルールが、ブログ記事プロジェクトに引きずられる (または逆に、別ディレクトリで消える)
- 「絶対に守ってほしい」ルールが、文字通り「メモリ依存」になっていて、ファイルとして残らないのでチームに共有できない
- ミスが再発しても、何が「メモリに入っているはず」だったかが追跡できない
- AI 自体が「いま自分が何を覚えているか」を、あなた以上に把握できていない
つまり 3 流の行動は、信頼できる記憶装置を持っていない ことに等しいのです。エージェントが「覚えました」と返事をしていても、それが翌日読み込まれる保証はなく、別プロジェクトに引き継がれる保証もなく、自分の言葉でルールを表現した文書も残りません。
2 流: vault に全部入れて、AI に検索させる (Obsidian × Claude Code 勢)
3 流のすぐ上にいるのが、Obsidian × Claude Code のセカンドブレイン勢です。彼らは markdown ファイルでルールや知識を 書き残している という点では 3 流より上です。しかしその構造は、「vault に全部入れて、Claude Code に vault 全体を読ませる」というものです。
これは確かに「明文化されたファイル」が残ります。しかし問題は、スコープ設計を放棄して全文検索に依存している 点です。動画字幕ルールも、リプライエージェントの口調定義も、経理 SaaS の API キー管理ルールも、全部一つの vault に並んでいる。AI は必要な時にそれを「検索」して引き出すことになります。
結果として、
- vault が肥大化するほど検索ノイズが増える (David R Oliver の Medium 記事は、まさにこの「dumping ground 化」で挫折した記録です)
- 関係ないルールがコンテキストに乗りやすく、トークン効率が悪い
- 「いま AI が何を読んだか」が不透明 (どの md ファイルが context に乗っているかが、AI の応答からしか分からない)
2 流は、3 流より「ファイルで残す」点では進化しています。しかし タスク単位のスコープ設計 という観点では、まだ「全部入り検索」に依存しています。
1 流: タスク単位の SOP ファイル + 必要時のみ注入
私が推奨する 1 流のやり方はシンプルです。
タスク単位で SOP (Standard Operating Procedure) ファイルを 1 個用意し、そのタスクを実行するときだけ、そのファイルだけを読み込ませる
具体的には、@ショート動画プロデューサー.md、@リプライエージェント.md、@SEOピラー記事プロデューサー.md のように、エージェントの役割ごとに 1 個の markdown を作ります。そして、動画を作るタスクのときだけ @ショート動画プロデューサー.md を Claude Code に読み込ませる ── つまり、コンテキストに何を載せるかを、人間が意図的にスコープ設計する のです。
これが構造化された記憶設計の核です。
| 軸 | 3 流 | 2 流 | 1 流 |
|---|---|---|---|
| 知識の所在 | エージェントのメモリ任せ | vault に全部 | タスク単位 SOP ファイル |
| 読み込みスコープ | 起動した瞬間に決まってしまう | vault 全文を検索される | 必要なファイルだけを意図的に注入 |
| 失敗時の改修 | 「もう一度メモリに入れて」と頼む | vault のどこかを編集 (どこか不明) | 該当 SOP に追記 |
| トークン効率 | 不明 | 悪い | 良い |
| 再現性 | 翌日もは保証ない | vault があれば残る | SOP がある限り再現 |
「メモリに入れて」が間違いな理由を、もう一度
ここで強調しておきます。「メモリに入れて」と頼むこと自体が、スコープ設計を AI に丸投げする行為 だから 3 流なのです。あなたが意図して ~/.claude/CLAUDE.md に書くなら、それは 1 流の行動です。あなたが意図して @リプライエージェント.md に追記するなら、それも 1 流の行動です。
決定的な違いは、「どのファイルに / どのスコープで」 書くかを、自分で設計しているかどうか にあります。これを AI に任せた瞬間、3 流に転落します。
5. 解決策: SOP ファイル + load_knowledge で必要時のみ注入する
具体的な 1 流の実装パターンを書きます。私の環境では、次の 3 つの要素で成り立っています。
要素 A: タスク単位の SOP markdown ファイル
エージェントの役割ごとに 1 ファイル。例えば私の SOP ライブラリ (一部抜粋):
prompts/
├── 実践Prompt/
│ ├── DailySeinfeld/DailySeinfeld_v2_JP.md # メルマガ起稿
│ └── SEOピラー記事/@00SEOピラー記事プロデューサー.md # SEO 記事 (本記事を生成しているプロンプト)
├── 初伝エージェント/
│ ├── コンテンツ制作エージェント/@00コンテンツ制作プロデューサー.md
│ └── 動画制作エージェント/@ショート動画プロデューサー.mdそれぞれの SOP には、
- 役割定義
- 入出力フォーマット
- フェーズ分割された手順
- 過去事故から追加された「やってはいけないチェックリスト」
- 関連ファイル / 関連エージェントへの内部リンク
が書かれています。1 ファイルあたり 3,000〜10,000 字程度。本記事を生成している @00SEOピラー記事プロデューサー.md は約 8,000 字あります。
要素 B: load_knowledge MCP による必要時注入
私は BlueLamp プラットフォーム上に load_knowledge という MCP ツールを実装してあります。これは「キーワード → SOP markdown 全文」の対応表を持っていて、load_knowledge(@SEOピラー記事プロデューサー) のように呼ぶと、その SOP の全文がエージェントの context に注入されます。
ポイントは、呼んだ時だけ注入される こと。動画を作るときに @ショート動画プロデューサー を、SEO 記事を作るときに @SEOピラー記事プロデューサー を、メルマガを書くときに DailySeinfeld_v2_JP を ── タスクの種類に応じて必要な SOP だけを注入します。これにより:
- 関係ない SOP は context に乗らない → トークン無駄ゼロ
- 「いま AI が何を見ているか」が明示的 (呼んだ SOP が context にある)
- SOP を更新したら、次回の呼び出しから自動で新版が反映される
load_knowledge は私の自前 MCP ですが、同様の発想は Claude Code のスラッシュコマンド や Claude Skills でも実装できます。重要なのは「タスク単位で markdown を切り、呼んだ時だけ読み込む」という構造です。
要素 C: 事故 → SOP 追記の運用ループ
ここが本質です。エージェント時代の「学習」とは、ミスが起きるたびに、該当する SOP ファイルにチェックリストを追記する人間の労働 です。AI が勝手に学ぶわけではありません。あなたが、ミスを「SOP のどこに / どう追記するか」を判断して書き込みます。
具体的な運用フローは次のようになります。
- エージェントが何らかのミスを犯す
- ミスの原因を どのタスクの / どの判断ステップで 起きたかに分解する
- その判断ステップを担っている SOP ファイルを特定する
- その SOP に「今後はこのチェックを必ず入れる」の 1 行を追記する
- 次回そのタスクを実行するとき、追記されたチェックが context に乗る → 同じミスを踏まなくなる
これを AI に頼らず人間がやる ことが、エージェンティックエンジニアの中心仕事です。AI に「次から気をつけて」と頼んでも、それは 3 流の繰り返しです。あなた自身が SOP の編集者にならない限り、エージェントは永遠に賢くなりません。
6. 実証ログ: Day 9 v1 → v2 — 23 分損失を SOP 4 項目追記で永久解決した実例
抽象論を続けても始まりません。実証データを公開します。3 日前 (Day 9)、私はリプライエージェントの YouTube ショート動画を作成していました。v1 で 4 つのミスを踏みました。
Day 9 v1 で実際に起きた 4 つの事故
| # | 事故内容 | 影響 |
|---|---|---|
| 1 | 字幕が cut #22 以降で消えた | 動画後半で視聴者が文脈を追えない |
| 2 | 数字「131」に単位が付かず、何の数字か分からない表示になった | 説得力の致命的低下 |
| 3 | TTS が「TikTok 平均 900 再生」を中国語読みした | ブランド毀損レベルの音声品質低下 |
| 4 | 元の台本が一部変更されていた (私の指示と乖離) | 再撮り直し |
再生成に 23 分 のロスでした。これは私個人の作業時間としても痛いですが、それ以上に「次回も同じミスを踏む可能性が残っている」ことが致命的です。
私が選ばなかった選択肢: 「メモリに入れて」
ここで多くの人がやる対応は、エージェントに「次から字幕を消すな」「数字に単位を付けろ」「英語の固有名詞は英語読みしろ」「台本を勝手に変えるな」と口頭で伝えて、「メモリに入れておいて」と頼む、です。
これをやると、
- 翌日別ディレクトリで動画を作ったら、メモリは引き継がれない (前述の通り Auto Memory はディレクトリ単位)
- たとえ同じディレクトリで作っても、Auto Memory に書かれた「字幕を消すな」が、context のどこに乗ったかが不透明
- チェック項目を後から見返すこともできない (ファイルとして可視化されていない)
つまり、23 分の損失が「再発防止できる資産」として残らない のです。
私が選んだ選択肢: @ショート動画プロデューサー.md のブラッシュアップ
私が実際に行ったのは、Claude Code に対して次の 1 行の指示を投げただけです。
「
@ショート動画プロデューサー.mdを読んで、今回の 4 つの事故が二度と起きないようにプロンプトをブラッシュアップして」
すると Claude Code は、SOP ファイルを読み込み、現状の構造を理解した上で、ファイルの 適切な位置に 次の 4 項目のチェックリストを追記しました。
## Phase 4 cut #22 以降の字幕生成チェック
- [ ] cut #22 以降の全 cut で per-cut burn-in が適用されているか
- [ ] overlay chain による字幕合成を禁止する (cut #22+ で消える既知バグ)
## Phase 5 数字の単位確認
- [ ] 「131」「900」等の数字が出てくる箇所すべてに、単位・意味を併記する
- 例: 「131 リプライ」「TikTok 平均 900 再生」
## Phase 6 TTS 固有名詞 lang 指定
- [ ] 英語固有名詞 (TikTok / YouTube 等) は SSML で <lang xml:lang="en-US"> を明示する
- [ ] 中国語読みされる事例: TikTok, ChatGPT, Claude
## Phase 2 台本変更検知
- [ ] 元台本 (storyboard_v1.md) と最終台本の diff を Phase 完了前に必ず取る
- [ ] 1 文字でも diff があれば、変更理由を Phase 完了報告に明記するこれで 同じミスは二度と起きません。なぜなら、次に動画を作るタスクで @ショート動画プロデューサー.md を load_knowledge で呼び出した瞬間、Claude Code はこの 4 つのチェックを初期コンテキストに乗せた状態で作業を始めるからです。
23 分の損失が「永続資産」に化けた
ここが核心です。23 分のロスは、ファイルに 4 項目追記された瞬間に チームの永続資産 に変わりました。
- 私が忘れていても、SOP が覚えている
- 私が別の Mac で作業を始めても、SOP ファイル (Git で同期) があれば同じ振る舞いになる
- 半年後に新しいメンバーが「ショート動画を作る」エージェントを動かしても、同じチェックリストが効く
- AI モデルが Opus 4.7 から 4.8 にアップデートされても、SOP は変わらないので挙動が安定する
これが、ミスを資産化する ことの実装です。「メモリに入れて」では、これは絶対に達成できません。
関連する設計事例: リプライエージェント 6 ステップ設計
リプライエージェントの設計フロー全体 (リサーチ → テスト → 本番 → 分析 → ブラッシュアップ → マネタイズ) は、別記事 リプライエージェントの作り方 — AIエージェント設計 6 ステップ で詳述しています。本記事の SOP 設計思想は、その 6 ステップの「⑤ ブラッシュアップ」フェーズに該当します。
そして、こうした SOP 駆動で動かしているエージェント群を組み合わせて 1 日で 100 倍規模の SaaS を完走させた実証データは エージェンティックエンジニアとは — 1 日 8 時間で経理 SaaS を完成させた 100 倍圧縮の設計思想 にあります。記憶設計と業務設計は、最終的に同じ場所で交差します。
7. Obsidian × Claude Code が「2 流」止まりな理由 — vault に全部入れる構造の問題
ここまで読んだ方は、巷で流行している「Obsidian + Claude Code でセカンドブレイン」設計が、なぜエージェンティックエンジニアの目から見ると 2 流止まり なのかが、もう分かっていると思います。整理します。
Obsidian × Claude Code の典型的セットアップ
YouTube で再生数 30 万を超えた Greg Isenberg × Vin の動画 (2026-02 公開、現時点 358K views) を起点に、Eric Tech、KJ Rainey、Productive Dude 等、3 ヶ月で 16 本以上の動画が累計 100 万再生を達成しています。共通する構成は次の通りです。
- markdown を一つの vault フォルダにまとめる
- vault ディレクトリで
claudeを起動する - Claude Code が vault 全体を read/write できる状態にする
/today/emerge/drift等の 自作スラッシュコマンド で vault を「思考パートナー」化
「markdown が AI native フォーマットだから」「Claude Code が中間層なしで直接 vault を読めるから」が、彼らの主な訴求点です。
この設計の良いところ (3 流より進化している点)
公平を期して、まず良い点を 3 つ書きます。
- ファイルとして残る: 「メモリに入れて」と頼むだけの 3 流に比べて、ルール・知識・思考が markdown ファイルとして可視化されます
- vendor lock-in がない: vault は所有権 100% の markdown フォルダなので、Obsidian を捨てても VS Code でも vim でも開けます
- graph view で関係性が見える: バックリンクのネットワーク表示は、PKM ツールとしては優秀です
ここは、純粋な PKM (Personal Knowledge Management) としては、Obsidian は強力です。
この設計の致命的な問題 (2 流止まりな理由)
しかしエージェント設計の文脈では、3 つの構造的問題があります。
問題 1: スコープ設計が「vault 全体」しかない
Claude Code を vault フォルダで起動する以上、context に乗りうる候補は vault 全体です。動画字幕ルールも、リプライ口調定義も、メルマガの SOP も、すべて一つの vault に並んでいる。AI はその中から「関連しそうな md」を検索 (キーワード一致 or プラグインによるベクトル検索) で引き出します。
ここで起きるのは、
- vault が肥大化するほど、検索ノイズが増える
- 「関係ないけど名前が似ている md」がしばしば context に乗る
- 「いま context にどの md が乗っているか」が、AI の応答からしか分からない
つまり スコープ設計が AI に丸投げされている のです。タスク単位で読み込む md を人間が意図的に選ぶ、という発想がそもそもないアーキテクチャです。
問題 2: 過剰メモリの罠 (context bomb)
「全部 vault に入れる」を続けると、必然的にトークン爆発が起きます。Vin 本人が動画内で「コマンド実行に 5 分以上かかる (大量ファイル read のため)」と言及しています。これは Claude API のレスポンス遅延ではなく、純粋に vault 全体を読み込むトークン量 によるものです。
タスク単位 SOP + load_knowledge の方式なら、必要な markdown だけが注入されるので、5 分待ちは絶対に起きません。本記事を生成している @00SEOピラー記事プロデューサー.md は約 8,000 字。1 タスクで context に乗る markdown はせいぜい 1〜3 ファイル、合計 1〜3 万字程度です。これが「軽い注入」の実態です。
問題 3: 改修先が不明瞭になる
vault に全部入れている設計だと、ミスが起きたときの修正先が不明瞭です。「字幕が消えた」というミスを、vault のどの md に追記すれば次回回避できるのか? daily/2026-05-21.md? projects/ショート動画.md? ideas/動画TIPS.md? 並び方が動画勢ごとにバラバラで、ベストプラクティスも統一されていません。
タスク単位 SOP 方式なら、答えは自明です。「ショート動画タスクで起きたミスは @ショート動画プロデューサー.md に追記する」。考える余地がありません。改修動線が一意である ことが、運用の安定性を生みます。
Obsidian にも残る正当な用途
ここまで Obsidian × Claude Code を 2 流と書きましたが、Obsidian そのものを否定しているわけではありません。個人のメタ認知 / 日次振り返り / 信念追跡 のような用途では、Obsidian のバックリンク + 日次ノート + slash commands は補完価値があります (これは私自身が深堀リサーチでも結論付けています)。
ただし、その用途においても 業務 SOP と個人 vault は完全分離 すべきです。動画字幕ルールは vault に入れない。経理 SaaS の API キー管理ルールも入れない。個人 vault には、あなたの思考の整理だけを入れます。これがエージェント時代の「Obsidian の正しい使い方」です。
ChatGPT のメモリ機能も同じ構造で 2 流
ついでに書いておくと、ChatGPT の「Memory」機能や Claude の「memory tool」も、同じ 2 流構造です。すべての会話で読み込まれてしまう (= スコープ設計がない)、何が記憶されているか不透明 (= 改修先が不明)、容量制限を超えると古いものが消える (= 永続性の保証がない)、という 3 つの欠陥を持っています。
エージェンティックエンジニアは、プラットフォーム提供のメモリ機能には依存しません。記憶は SOP ファイル + Git + load_knowledge MCP のように、自分で設計してファイルに落とした構造 だけを信頼します。
よくある質問 (FAQ)
Q1: CLAUDE.md と CLAUDE.local.md の違いは何ですか?
./CLAUDE.md はチームで共有する想定 (Git にコミット)、./CLAUDE.local.md は個人のローカル設定 (Git ignore 対象) です。優先順位は CLAUDE.local.md > CLAUDE.md > ~/.claude/CLAUDE.md の順で、後の階層が前の階層を上書きします。チーム共通ルールは ./CLAUDE.md に、自分専用の癖や API トークンの場所は ./CLAUDE.local.md に書き分けます。
Q2: Claude Code がディレクトリを越えてメモリを保持できないのはなぜですか?
Claude Code の Auto Memory は ~/.claude/projects/<ディレクトリパスのハッシュ>/memory/ 配下に保存される プロジェクトスコープ の設計だからです。これは仕様であって不具合ではありません。横断したいルールは ~/.claude/CLAUDE.md (ユーザー全体) に書く必要がありますが、すべてのプロジェクトの context に毎回乗るため、本当に全プロジェクト共通の絶対ルールだけに限定すべきです。
Q3: Obsidian × Claude Code は完全に無価値ですか?
いいえ。業務 SOP の管理 には不向き (本記事で「2 流」と書いた理由) ですが、個人のメタ認知 / 日次振り返り / 信念追跡 の用途では補完価値があります。重要なのは、業務 SOP と個人 vault を完全分離することです。vault に業務知識を入れないこと、AI に vault を書かせないこと、この 2 つを守れば、Obsidian は個人脳の延長として有用です。
Q4: 「SOP ファイル」とは具体的にどんな構成ですか?
役割定義 / 入出力フォーマット / フェーズ分割された手順 / 過去事故から追加されたチェックリスト / 関連エージェントへの内部リンク、の 5 ブロック構成が基本です。1 ファイル 3,000〜10,000 字程度。本記事を生成している @00SEOピラー記事プロデューサー.md は約 8,000 字で、Phase 1 (KW リサーチ) から Phase 7 (完了報告) までの 7 フェーズワークフローと、各フェーズの過去事故事例が記載されています。
Q5: 「ミスが起きたら SOP に追記」を毎回やるのは現実的ですか?
最初は手間に感じますが、追記された SOP は 一度書けば永続資産 になるので、3-6 ヶ月で回収できます。私の場合、月に 5-10 件のチェックリスト追記を行いますが、過去の追記により回避できているミスが累積していくため、運用 6 ヶ月時点でエージェントの精度は導入初期の 2-3 倍に向上しました。ミスを「23 分の損失」で終わらせず「永続的な再発防止」に変換する、これがエージェンティックエンジニアの中心仕事です。
Q6: load_knowledge MCP の代わりに、何を使えばよいですか?
load_knowledge は私の自前 MCP サーバですが、同様の発想は標準機能でも実装できます。① Claude Code のスラッシュコマンド (プロジェクト or グローバルで .claude/commands/<name>.md を置き、/<name> で本文を context に注入) ② Claude Skills (公式の Skill 機能で markdown を読み込ませる) ③ 単純に「プロジェクト直下に prompts/ フォルダを作って必要な md を Read tool で読ませる」だけでも十分動きます。重要なのは MCP の有無ではなく、「タスク単位で markdown を切る / 必要時だけ読む」の設計原則です。
まとめ — 記憶を設計するのは AI ではなく、あなた自身です
最後に、本記事のエッセンスを 5 行に圧縮します。
- Claude Code は 会話ごとに脳がリセットされる エージェント。覚えていられるのは CLAUDE.md (4 階層) と Auto Memory (プロジェクト単位) だけ
- Auto Memory はディレクトリが違えば別の脳。だから「翌日忘れる」は仕様。ディレクトリ横断したいルールは
~/.claude/CLAUDE.mdに意図的に書く - 「メモリに入れて」と頼むのは AI 利用 3 流。スコープ設計を AI に丸投げしている時点で、その記憶は信頼できる資産にならない
- Obsidian × Claude Code でセカンドブレインを作るのは 2 流。ファイル化までは進化しているが、vault 全文検索に依存しているため改修動線が不明瞭
- 1 流はタスク単位の SOP ファイル + 必要時のみ注入。ミスが起きるたびに SOP に追記し、永続資産化する
エージェント時代の「学習」は、AI が勝手にやるものではありません。あなたが、SOP ファイルの編集者として、ミスを永続資産に変換する作業そのもの が学習です。これを理解した瞬間、エージェントは確実に賢くなり始めます。理解しないまま「メモリに入れて」と頼み続ければ、永遠に同じミスを踏みます。
そしてこの設計思想は、リプライエージェント、動画生成、SEO 記事、経理 SaaS など、業務を AI に丸ごと渡す すべてのタスク で共通します。タスクが変わっても、構造は変わりません。
関連記事:
- リプライエージェントの作り方 — AIエージェント設計 6 ステップで「労働」を「資産」に変える完全フロー
- エージェンティックエンジニアとは — 1 日 8 時間で経理 SaaS を完成させた 100 倍圧縮の設計思想
- Claude Code 完全ガイド — 公式 CLI で始める AI エージェント開発
出典:
- Anthropic 公式 Claude Code ドキュメント (Memory and CLAUDE.md)
- Anthropic 公式 Claude Code ドキュメント (Settings and configuration)
さらに深く学びたい方へ: 本記事で書いた SOP 駆動のエージェント設計を、自社の業務に組み込みたい経営者・起業家の方は、6 月 6 日〜8 日に名古屋で開催する 大和 VIP 合宿 (3 日間 / 50 名締切) で実装手順を直接共有しています。詳細は 大和ViSiONARY のオープンチャットからご確認ください。あるいは、SOP 駆動のエージェント運営を自社の現場でゼロから組み立てたい方は、BlueLamp の AI 業務代行エージェントをご検討ください (https://bluelamp.ai/)。
この記事が役立ったなら、次のステップへ
専門家と一緒に、あなたのAI活用を加速させましょう
白石達也
BlueLamp創業者。52のAIエージェントを開発し、企業のAI導入を支援。 Aquaphotomics MCP(12,800+論文処理)開発者。Claude Code専門家。
プロフィールを見る →